Publications
selected papers and preprints.
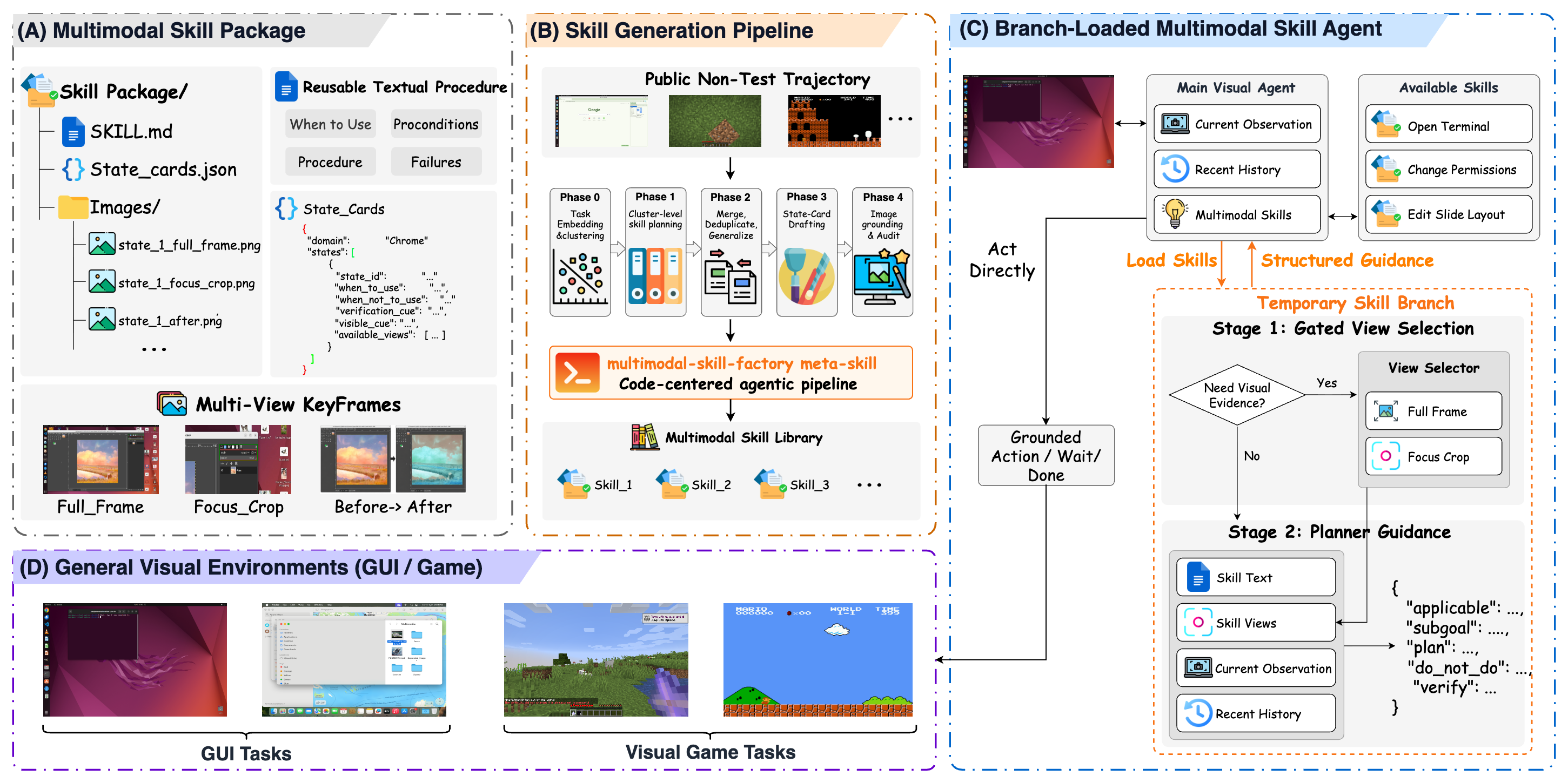
MMSkills: Towards Multimodal Skills for General Visual Agents
arXiv preprint, 2026
MMSkills represents reusable multimodal procedural knowledge for visual agents with textual procedures, runtime state cards, and multi-view keyframes, then uses branch loading to consult relevant visual evidence during decision making.
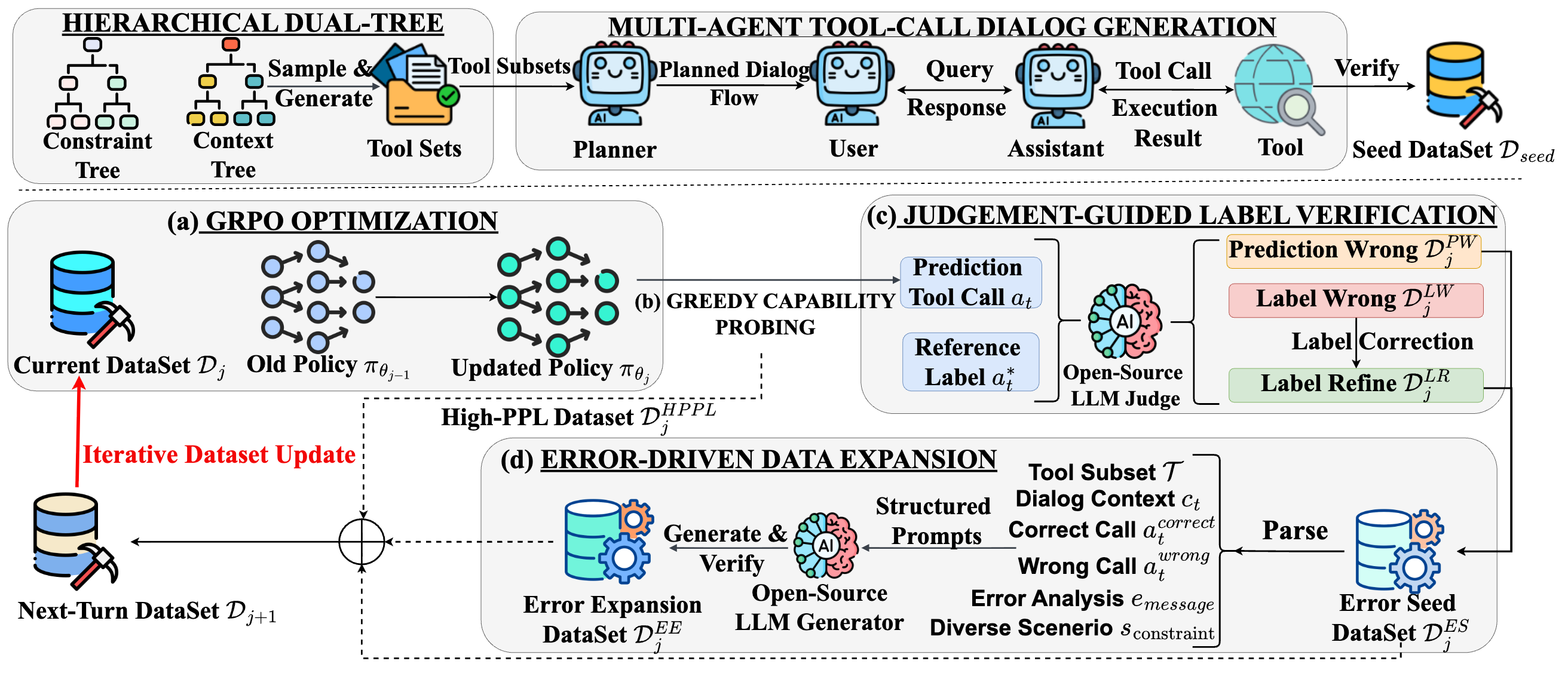
LoopTool: Closing the Data-Training Loop for Robust LLM Tool Calls
Annual Meeting of the Association for Computational Linguistics (ACL), 2026
Main Conference
LoopTool closes the data-training loop for LLM tool use by evolving training data around a model's current weaknesses, improving robustness for multi-step tool-calling tasks.
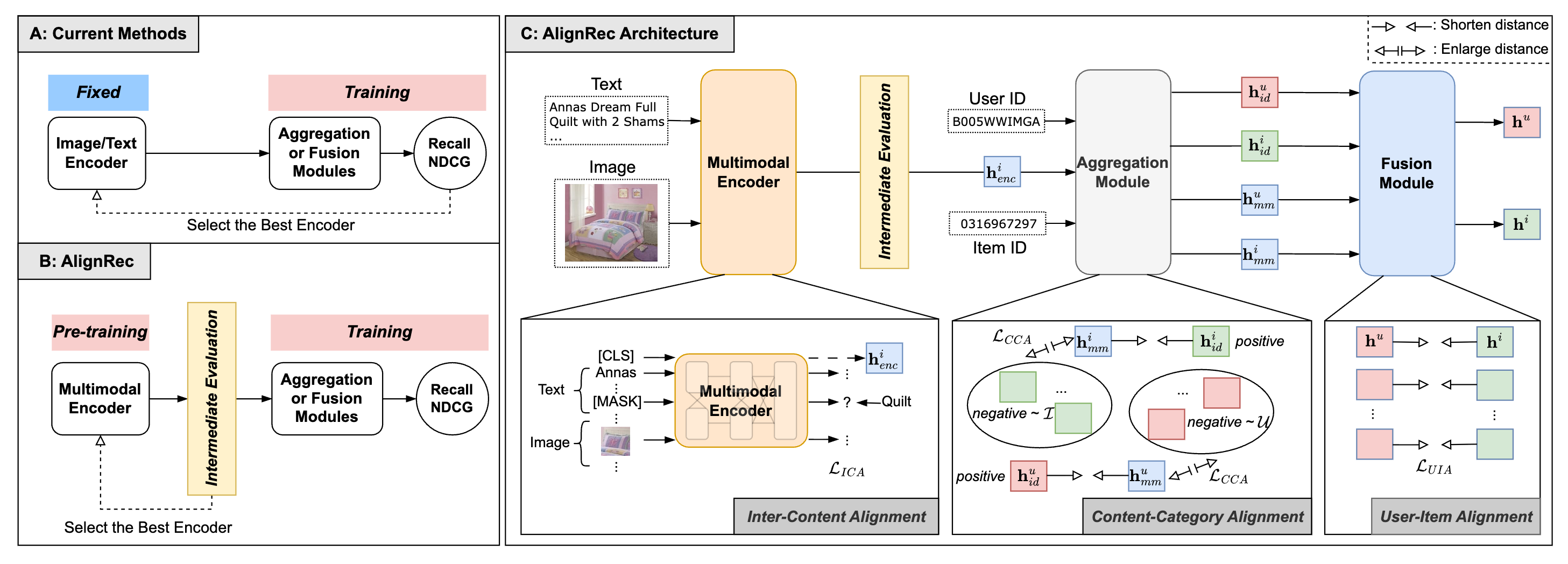
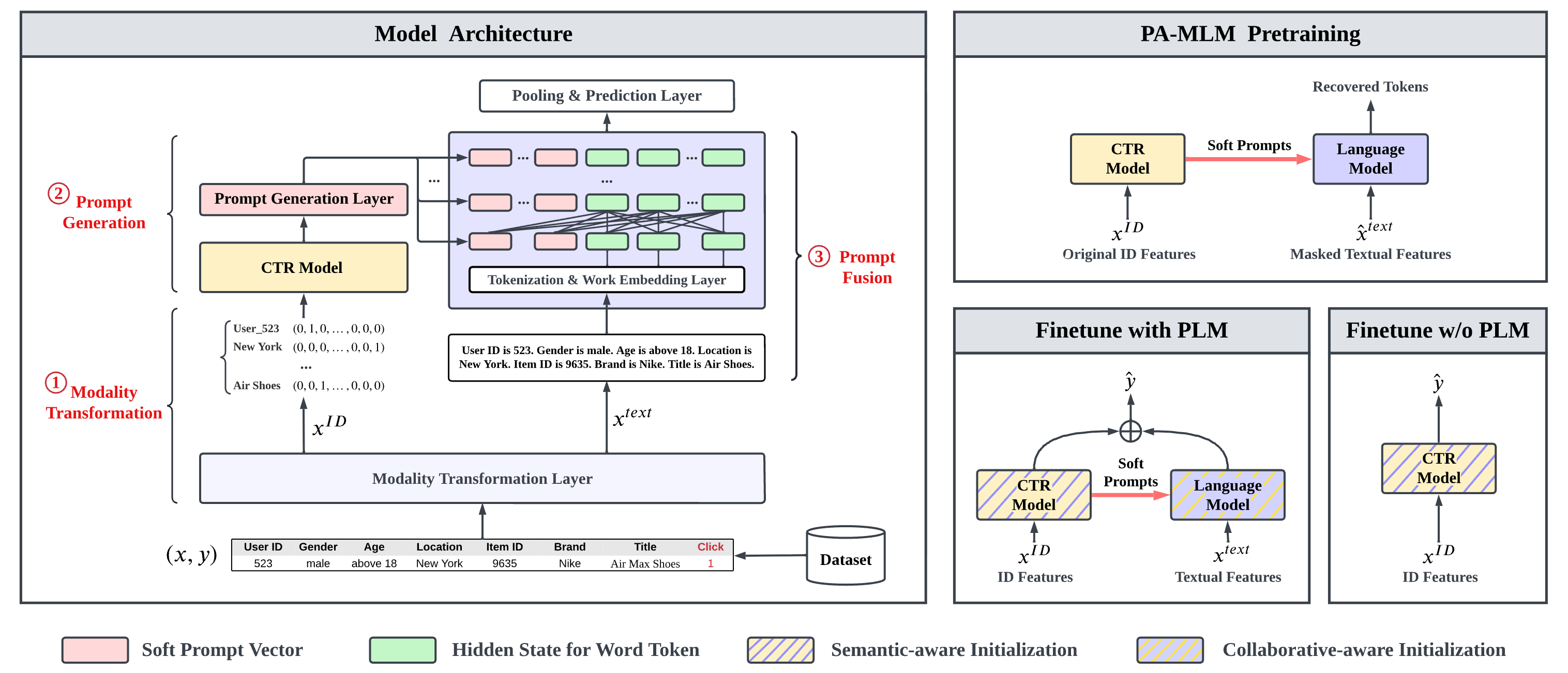
AlignRec: Aligning and Training in Multimodal Recommendations
ACM International Conference on Information and Knowledge Management (CIKM), 2024
AlignRec studies representation misalignment in multimodal recommendation and introduces alignment-aware training for stronger multimodal user-item features.
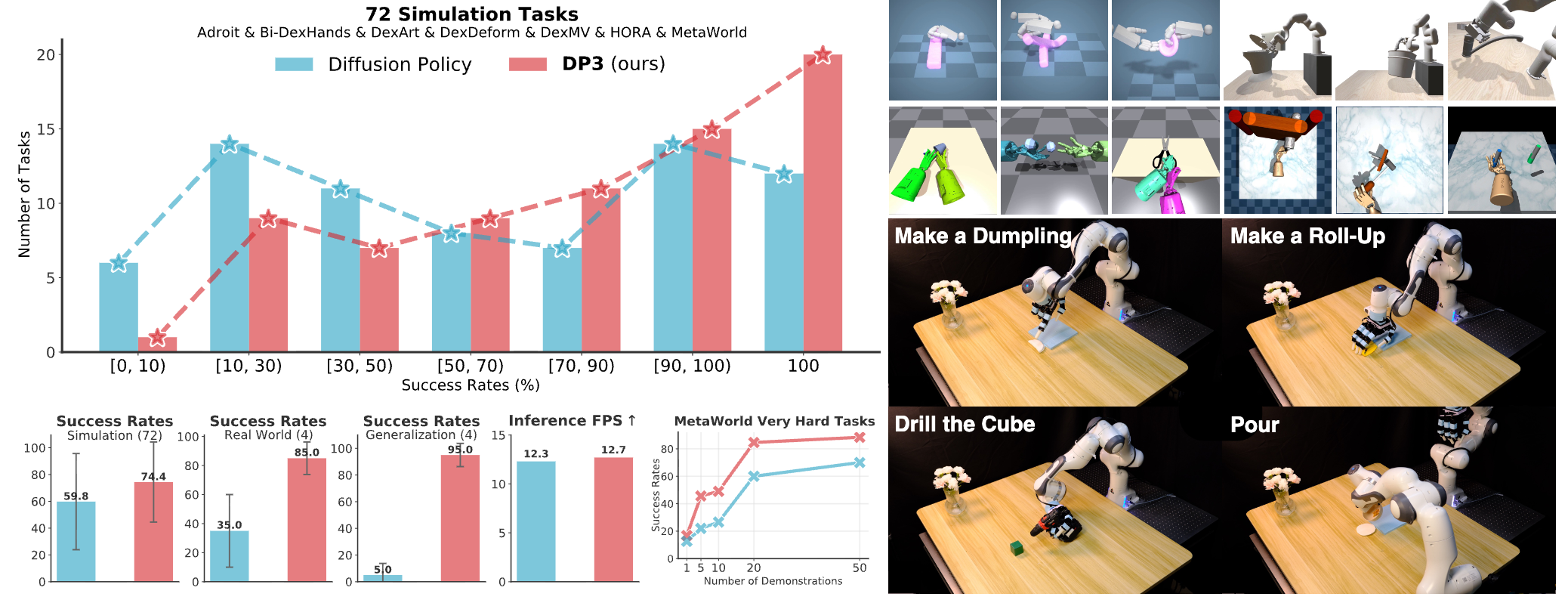
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
Robotics: Science and Systems (RSS), 2024
3D Diffusion Policy introduces compact point-cloud representations into diffusion-policy imitation learning for stronger robot manipulation generalization.
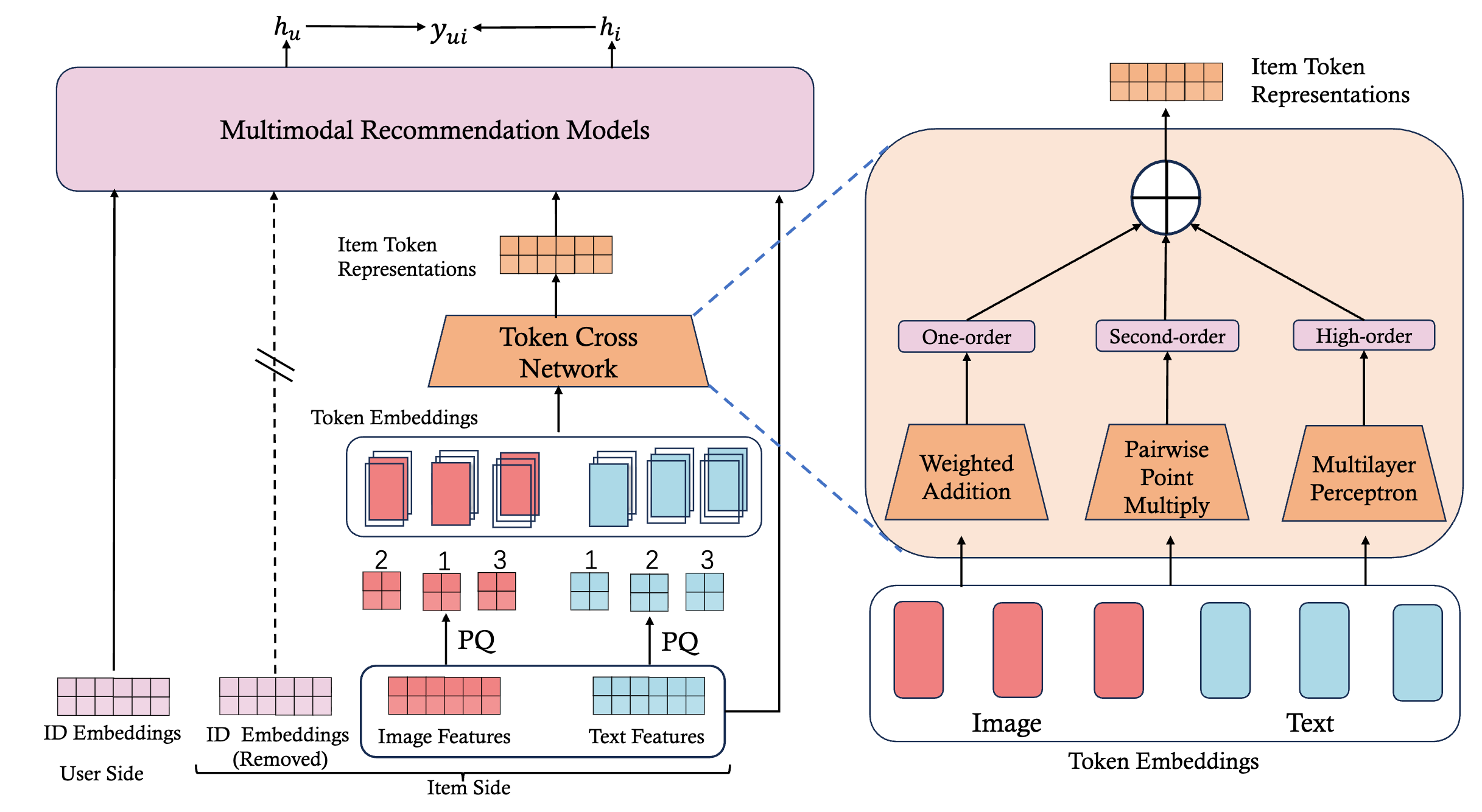
Learning ID-free Item Representation with Token Crossing for Multimodal Recommendation
European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML-PKDD), 2026
CCF-B
MOTOR replaces item ID embeddings with learnable multimodal tokens and a token-crossing network, reducing reliance on sparse ID features.
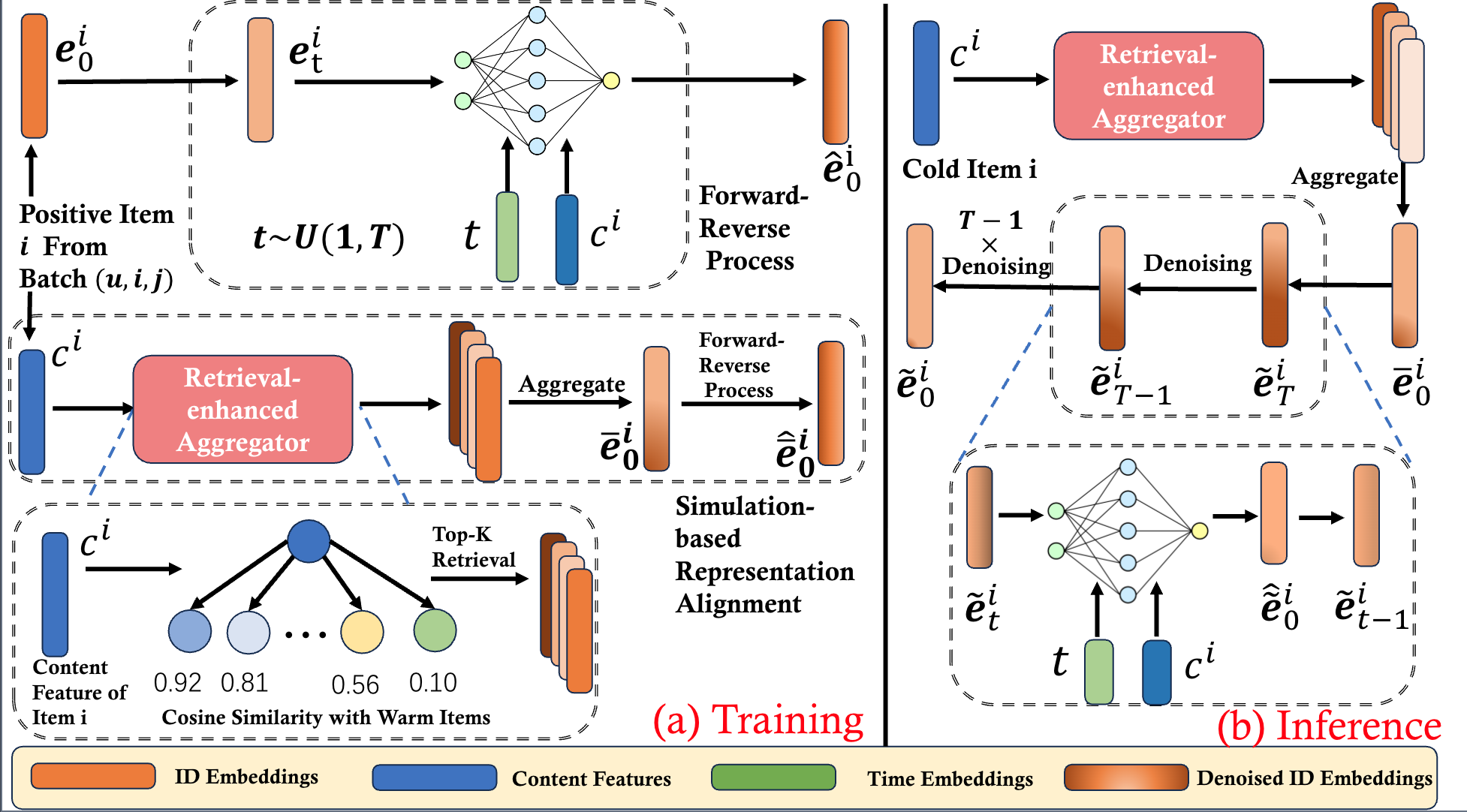
DiffCold: A Diffusion-based Generative Model for Cold-Start Item Recommendation
European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML-PKDD), 2026
CCF-B
DiffCold tackles cold-start recommendation with diffusion-based representation simulation, retrieval-enhanced aggregation, and representation alignment for cold items.
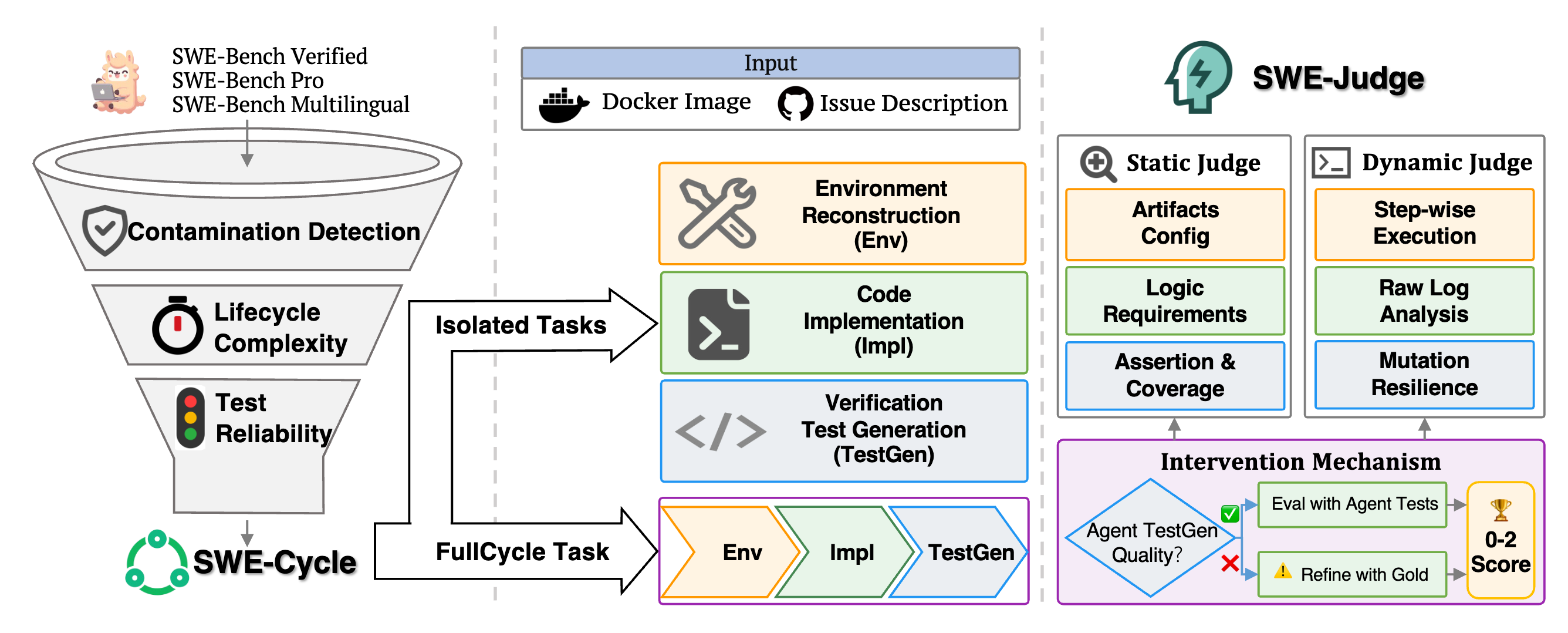
SWE-Cycle: Benchmarking Code Agents across the Complete Issue Resolution Cycle
arXiv preprint, 2026
SWE-Cycle evaluates code agents across environment reconstruction, implementation, test generation, and a full-cycle issue-resolution task.
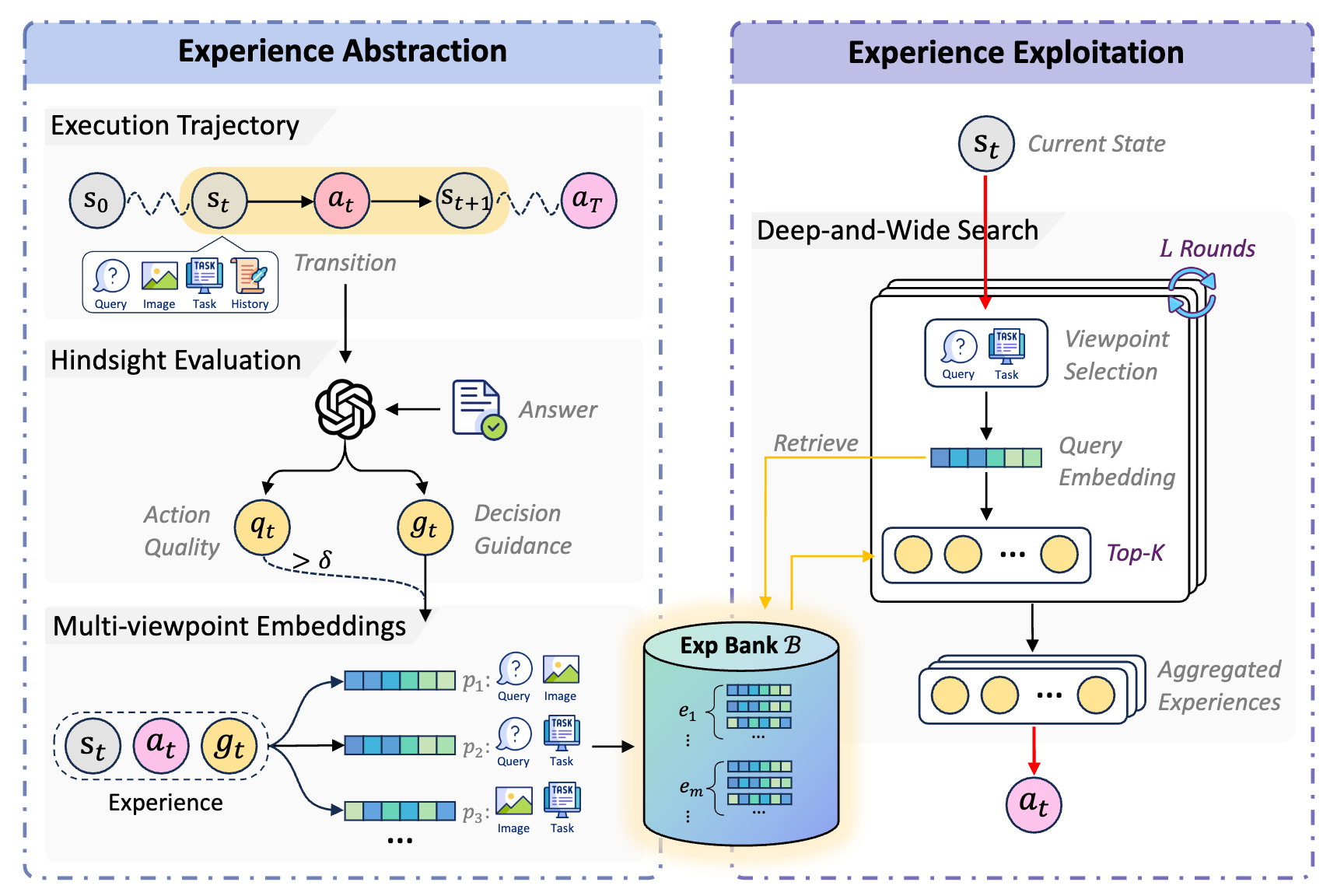
MuSEAgent: A Multimodal Reasoning Agent with Stateful Experiences
arXiv preprint, 2026
MuSEAgent distills interaction histories into stateful decision experiences and retrieves them through complementary search strategies for multimodal reasoning.
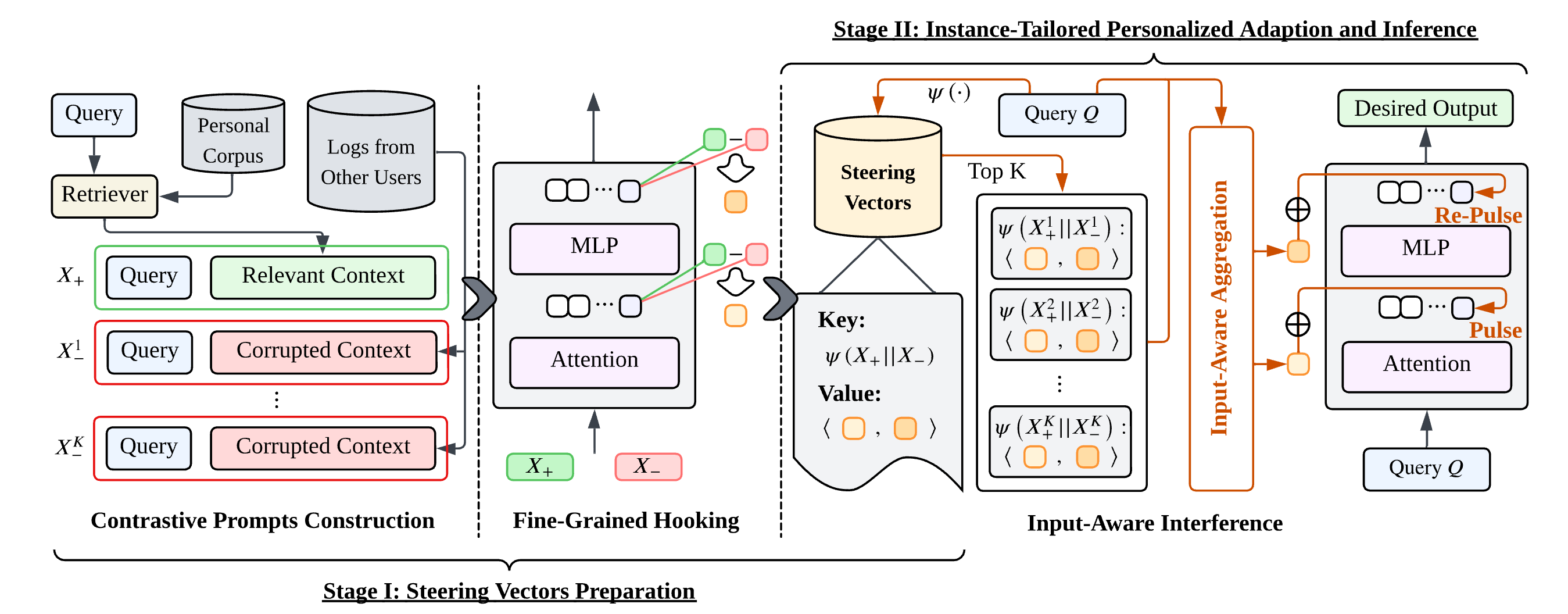
Fints: Efficient Inference-Time Personalization for LLMs with Fine-Grained Instance-Tailored Steering
arXiv preprint, 2025
Fints performs inference-time personalization by selecting fine-grained, instance-tailored steering signals for dynamic user preferences and sparse personalization data.
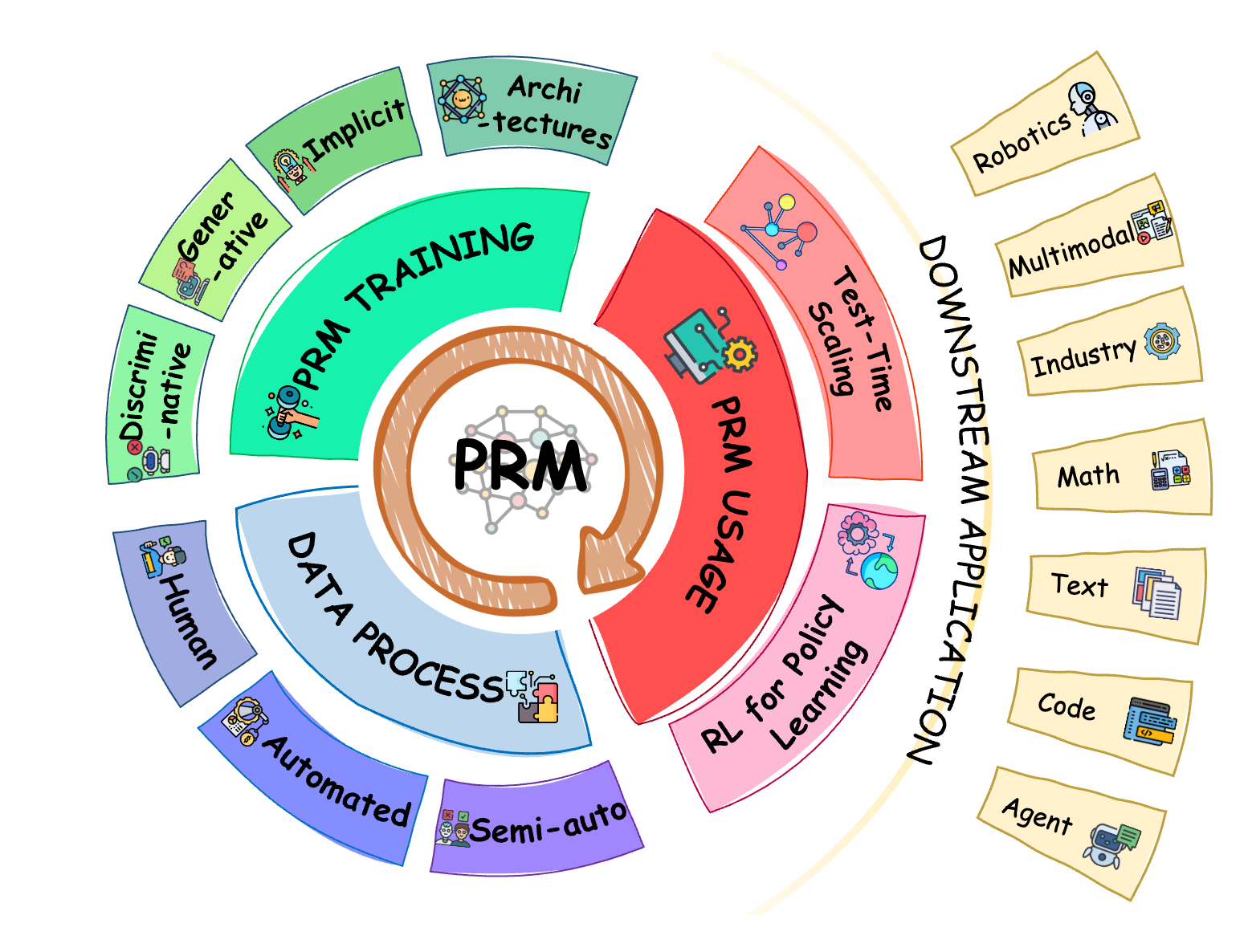
A Survey of Process Reward Models: From Outcome Signals to Process Supervisions for Large Language Models
Annual Meeting of the Association for Computational Linguistics (ACL), 2026
Main Conference
This survey reviews process reward models across process data construction, reward modeling, test-time scaling, and reinforcement learning for large language models.
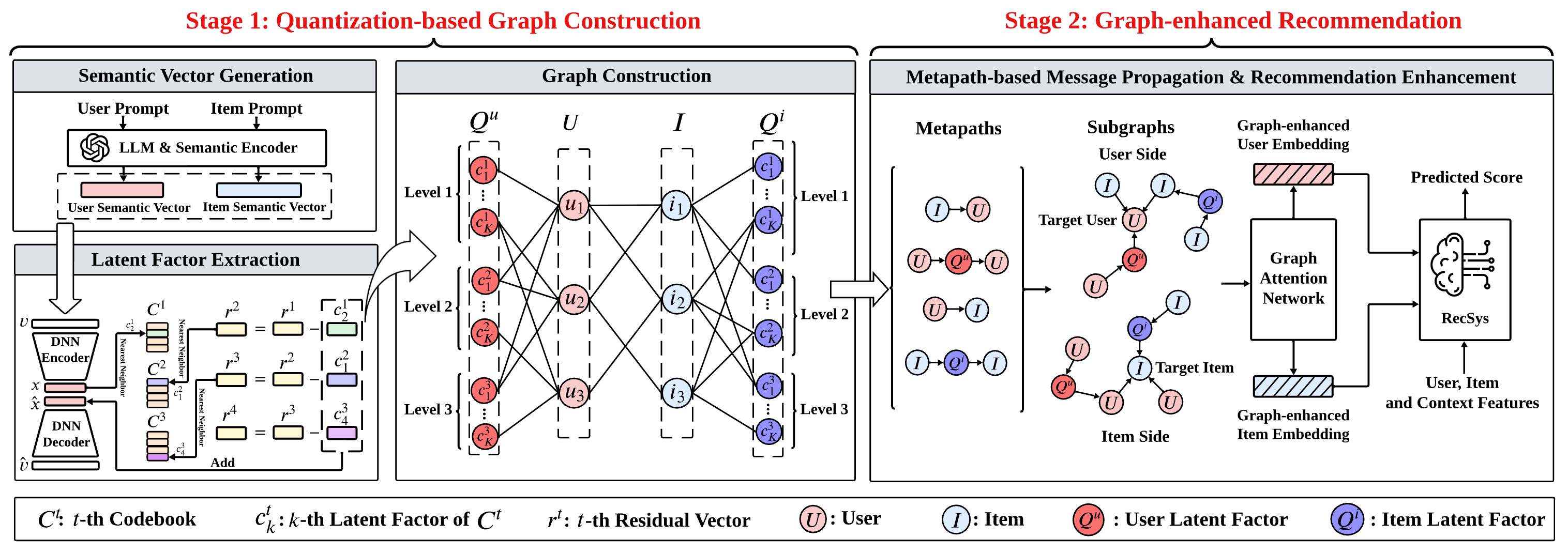
An Automatic Graph Construction Framework based on Large Language Models for Recommendation
ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2025
This framework uses large language models to automate graph construction for recommendation, improving the graph learning substrate used by GNN-based recommenders.